cross validation是我們在建模時常常要使用的方法,主要的功能是避免overfitting的問題, 也是我們調參數後可以互相評估比較的手法,今天來聊聊cross validation的種類~
在切割資料時,我們常做train-test split,把資料切成兩組,使用training做模型,test做驗證,而cross validation就是用不同的方法切割資料很多次,每次利用不同的資料訓練模型,常見的方法有:
Leave-one-out cross validation: 最極端的切割方法,將每個資料點輪流當成test,剩餘當成train,用這個方法訓練模型代表要花費n-1倍的時間(n是data size),假設今天有十個資料點,這個方法就會建立十個不同的模型再平均他們的表現。
K-fold cross validation: 比較常見的方法,也就是把資料隨機分成k組,每次拿一組當成test,剩餘組當成train,當你設定k=n,就等於在執行leave-one-out cv。一般會把K設定為5-10的範圍。另外一個會聽到的名詞是"stratified",也就是下方的右圖,stratified是發生在如果資料裡有類別變數,這種方法會確保在每一個組裡類別變數的比例是一致的。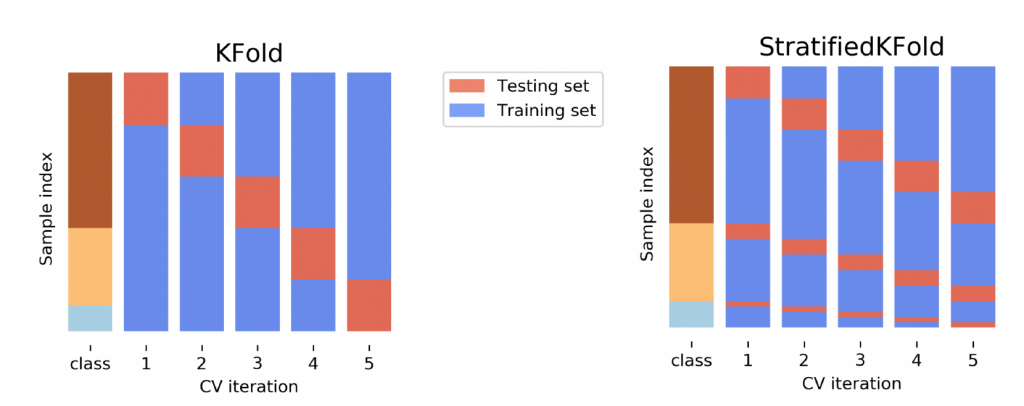


 iThome鐵人賽
iThome鐵人賽